随着文本大模型技术的崛起,语音合成领域正迅速适应这一变革,基于大模型的语音合成技术因其卓越性能而成为行业趋势。
尽管传统语音合成在音质和韵律方面已高度仿真,但在有声书、自然对话等复杂场景的情感与语调细节上仍有不足。大型语言模型(LLM)的兴起为弥补这些差距提供了新的可能性,引领语音合成技术向更真实、更自然的交互体验迈进。
自出门问问发布第一代TTS引擎起,历经多次迭代,语音合成效果不断趋近“以假乱真”,媲美真人。
出门问问的语音合成技术不断迭代
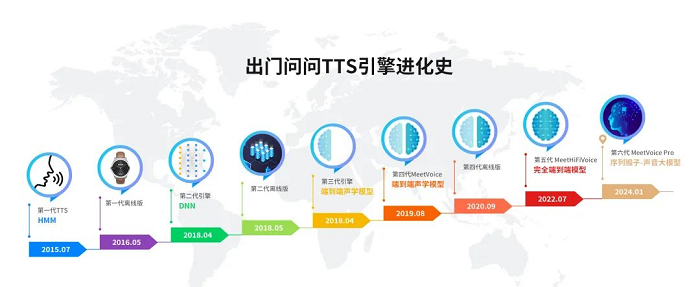
自2015年推出初代TTS引擎以来,出门问问通过不断迭代,显著提升了语音合成的真实度。2019年8月,我们发布了先进的第四代引擎MeetVoice,集成至其产品线和ToB服务,并在「魔音工坊」中实现上千款声音的大规模应用,获得广泛好评。面对短视频市场的快速增长和用户对高仿真语音的需求,我们不断优化MeetVoice引擎,增添了包括停顿调节、高清音质、语调控制等多项功能。
现在,出门问问的自研大模型「序列猴子」取得显著突破,其以语言为核心的能力体系,涵盖“知识、对话、数学、逻辑、推理、规划”六个维度。特别的是,该模型拥有优秀的跨模态知识迁移能力,能够将语言模型所涵盖的常识知识有效转化应用于其他非语言模态的模型当中。基于此技术,开发团队利用前沿的文本大模型技术构建了一套先进的语音合成系统——MeetVoice Pro,即出门问问第六代TTS引擎。该系统基于序列猴子的文本模型能力,通过对海量语音样本的深度学习训练,能够产生极富自然感和表现力的合成声音,使AI配音的效果已然接近真实人声的水准。
「序列猴子」赋能语音合成引擎
为了深入理解我们所开发的新一代语音合成引擎的技术要点,让我们逐步梳理其核心架构。
01语音token化
首先,我们需解决的关键问题是将语音信号有效转化为机器可处理的形式。不同于文本数据的离散特性,语音信号呈现为一种连续波形,这为语音合成引擎带来了初始的挑战。针对这一难题,我们采纳了行业内广泛认可的Encoder-Decoder架构策略,以实现对连续语音信号的有效离散化处理。通过本架构,语音数据首先被分解为一系列离散单元,即所谓的“语音tokens”。这一过程不仅为后续的语音生成打下了坚实基础,同时也保证了合成语音的自然度和流畅性。
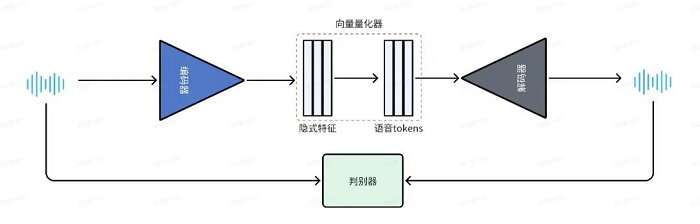
语音编解码器架构图
02 对文本及语音token进行建模
在进行文本和语音token的建模过程中,我们自研的大型序列模型「序列猴子」扮演了重要角色。该模型利用其先进的文本基座(underlying textual foundation)能力,实现了对多音字、韵律和上下文关系的深入理解和精准模拟,进而将这些文本属性有效地映射(或迁移)到语音领域。通过这种方式,「序列猴子」不仅提高了语音token的生成质量,也增强了模型对复杂语音现象的处理能力。

基于大模型「序列猴子」的语音合成框架
三个优势 促成真实人声感受
在新框架的支持下,本次的语音合成技术呈现出了三个突出的优势,在真实性方面获得了极大的提升。
01自动调节情感和韵律
新技术可以在讲述一个悲伤的故事时降低音调,增加柔和度,或者在分享兴奋的新闻时提升语速,加强语气的振奋感。如此智能的调节,让合成语音的体验更加自然、富有表现力,仿若置身于真实的人类对话之中。
02声音克隆仅需数秒
声音克隆变得异常高效,它能够快速学习仅数秒钟的音频样本,生成高度逼真的音频,这样一来,传统耗时的录音过程和训练过程将成为历史。例如,我们能够用埃隆·马斯克和史蒂夫·乔布斯短暂的原声录音,仅需等待数秒,轻而易举地克隆出非常相似的声音。
03 跨语种音色迁移
该技术具备强大的跨语言能力,已实现将不同语言的音频无缝转换为同音色中文或英文,小语种发音者能够流畅地使用中文或英文进行交流。比如,我们可以让一位母语为泰语的女孩使用自己的音色来流利地用英文做自我介绍,用中文背诵古诗。
至臻发音人 适用多个场景
在众多已上线的发音人中,我们经过优中选优,甄选出一批既独特又品质出众的声音,推荐给广大内容创作者使用。
01有声书
02影视解说
03其他特色
限时免费 体验有礼
1月31日至2月28日期间,「魔音工坊」推出特别活动,至臻发音人系列将对所有SVIP会员免费开放,非会员用户可使用CDK兑换码 AIGC2024 免费获得1天SVIP会员进行体验。欢迎点击以下小程序使用相应发音人。

您在体验过程中遇到任何问题或意见,均可在公众号后台即时反馈,我们将随机赠送参与者1天的SVIP会员体验资格。
目前,出门问问 AIGC 产品累计服务的用户数量已超 1200 万,注册用户数量超 800万,其中付费的用户数量超 60 万。据灼识咨询行业报告,出门问问是亚洲起步最早、收入规模最大的专注于生成式 AI 的人工智能公司。